Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference


Quantization Framework for Fast Spiking Neural Networks. - Abstract - Europe PMC

2106.08295] A White Paper on Neural Network Quantization

Pruning and quantization for deep neural network acceleration: A survey - ScienceDirect

PDF] hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices

PDF] Bayesian Bits: Unifying Quantization and Pruning

PDF] Channel-wise Hessian Aware trace-Weighted Quantization of Neural Networks
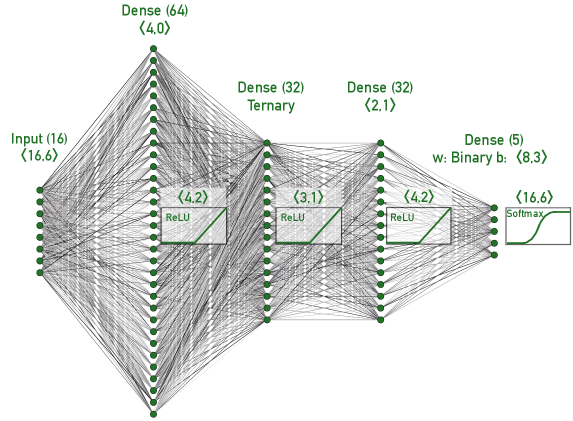
2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors
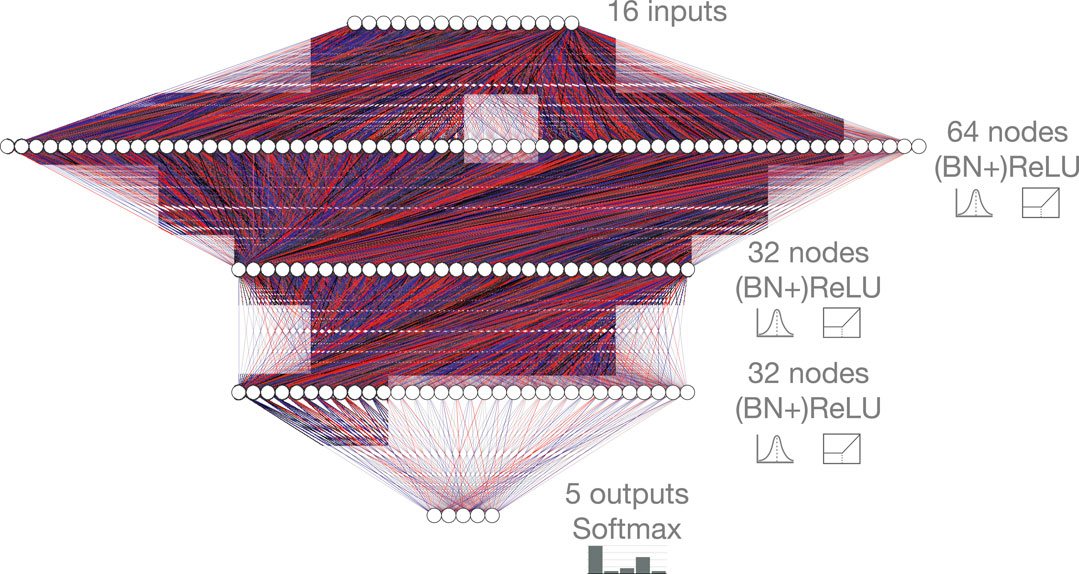
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
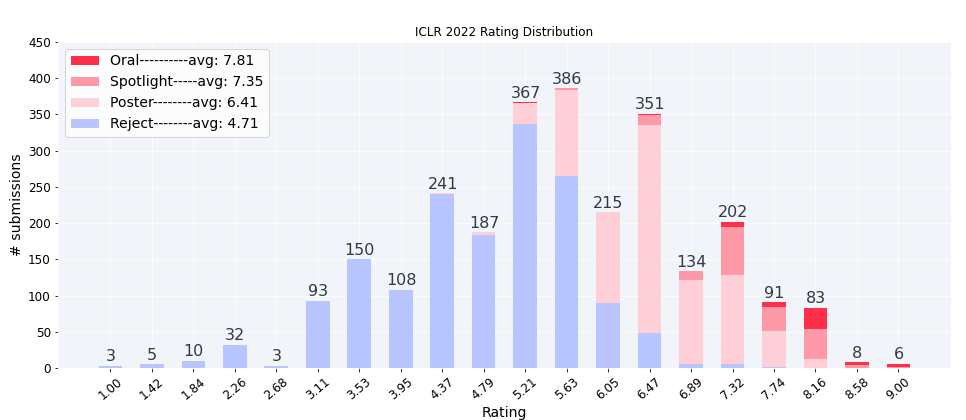
ICLR2022 Statistics
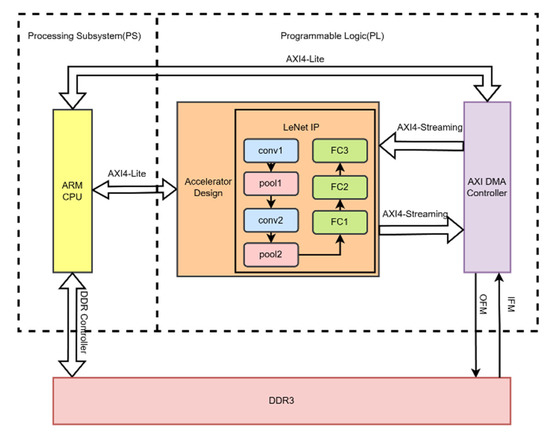
Sensors, Free Full-Text

Enabling Power-Efficient AI Through Quantization







